Introduction
The sensor-dht11 utility from the WildlifeSystems project has been
rewritten from Python to C to reduce dependencies, improve startup time,
and provide more reliable sensor readings on Raspberry Pi devices. This
report analyses benchmark results comparing the performance of the two
implementations.
Improving the performance of a sensor that is read infrequently (once per minute) may not seem critical, but the current deployment at the Natural History Museum’s Urban Research Station involves reading 25 DHT11 sensors every minute across multiple nodes. Over a year this is over 13 million reads.
The DHT11 sensor requires precise timing for communication, and is known to be tricky to read reliably. Both implementations include retry logic with back-off delays when a read fails, so the benchmark measures both the time taken per read and the number of attempts required.
The source code is available at github.com/Wildlife-Systems/sensor-dht11.
Background
The DHT11 Sensor
The DHT11 is a low-cost digital temperature and humidity sensor commonly used in environmental monitoring applications. It uses a single-wire serial interface to communicate with the host microcontroller or computer, transmitting 40 bits of data (16-bit humidity, 16-bit temperature, 8-bit checksum) in response to a start signal.
Key characteristics:
- Temperature range: 0–50°C (±2°C accuracy)
- Humidity range: 20–80% RH (±5% accuracy)
- Sampling rate: Maximum 1 Hz (one read per second)
- Communication: Proprietary single-wire protocol with precise timing requirements
The timing-critical nature of the DHT11 protocol makes it challenging to read reliably from user-space on Linux systems, where process scheduling can introduce jitter. Both implementations include retry logic to handle failed reads.
Original Python Implementation
The original implementation used Python 3 with the Adafruit CircuitPython libraries:
- Primary dependencies:
adafruit-circuitpython-dht,adafruit-blinka,RPi.GPIO - Runtime requirements: Python 3.x interpreter, multiple Python packages with native extensions
- Limitations:
- Slow startup due to Python interpreter initialization
- Large dependency tree (~50-100MB with virtual environment)
- Complex installation requiring pip and virtualenv (this was handled in the Debian packaging, but added complexity and further dependencies)
New C Implementation
The new implementation is a single native C binary:
- Dependencies: Only
libgpiodshared library - Binary size: ~30KB (vs ~50-100MB for Python with venv)
- Startup time: <10ms (vs ~0.5-1.0s for Python)
- Key features:
- Direct GPIO access via libgpiod
Benchmark Methodology
Two complementary benchmarks were conducted to evaluate performance:
Raw Sensor Reading Benchmark
This benchmark measures the internal sensor read time within each implementation, bypassing process startup overhead. It captures the time spent communicating with the DHT11 sensor and processing the response.
- Test hardware: Raspberry Pi (arm64)
- Sensor: DHT11 temperature and humidity sensor on GPIO pin 4
- Number of reads: n = 2000
- Measurements: Time per read (seconds) and number of retry attempts required
- Benchmark script: run_benchmarks.sh
Full System Benchmark
This benchmark measures the total end-to-end execution time of invoking each binary, including process startup, library loading, sensor reading, and JSON output generation. This reflects real-world usage where the binary is called by an external scheduler.
- Test hardware: Raspberry Pi (arm64)
- Number of invocations: n = 100
- Measurements: Real time, user CPU time, and system
CPU time (via
/usr/bin/time) - Benchmark script: run_system_benchmarks.sh
Data
Raw Reading Benchmarks
System Benchmarks
Part 1: Raw Sensor Reading Benchmarks
This benchmark measures the internal sensor read time within each implementation, including retry delays when a read fails. The benchmark scripts call the sensor reading functions directly, bypassing startup overhead.
Note: 1 C read(s) and 0 Python read(s) failed after exhausting all retry attempts and are excluded from the analysis.
Summary Statistics
| Implementation | Mean Time (s) | Median Time (s) | SD Time (s) | Min Time (s) | Max Time (s) | Mean Attempts |
|---|---|---|---|---|---|---|
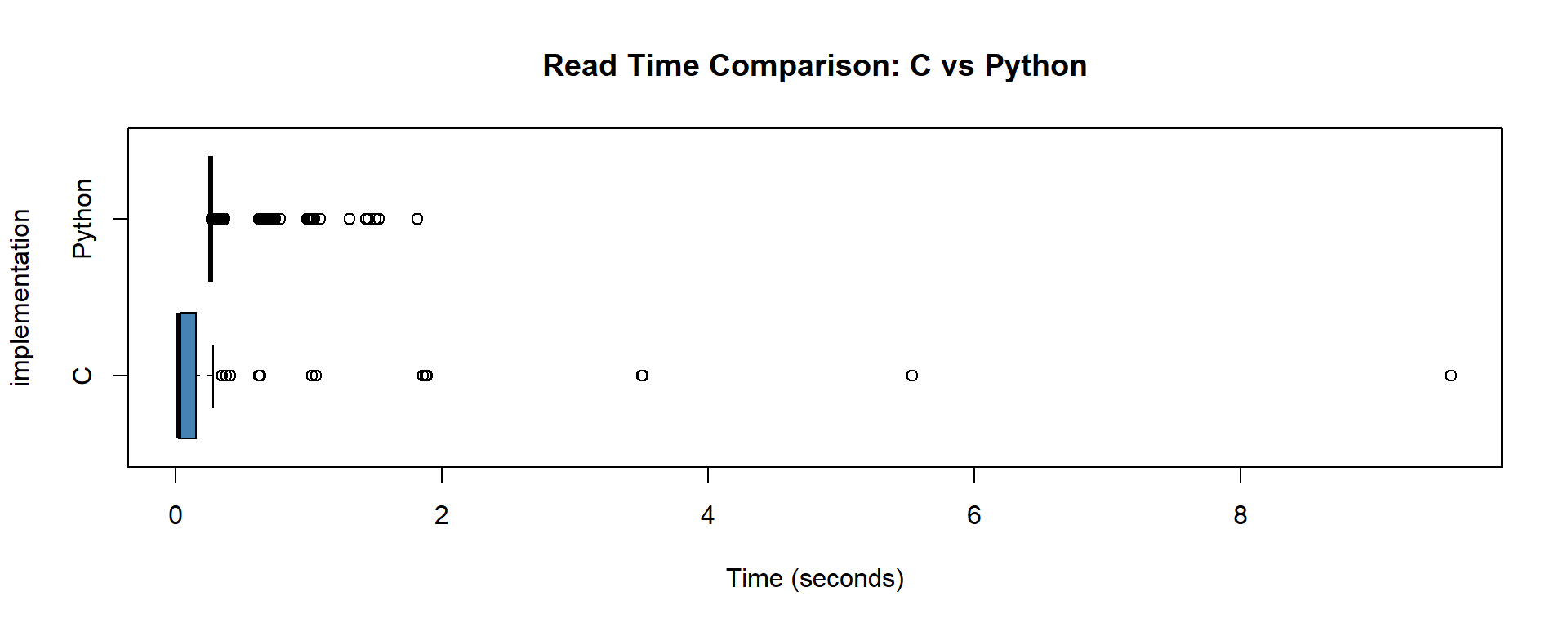
| C | 0.1387 | 0.0258 | 0.3793 | 0.0253 | 9.5838 | 1.6978 |
| Python | 0.3141 | 0.2628 | 0.1457 | 0.2615 | 1.8183 | 1.1205 |
Key finding: The C implementation averages 0.1387 seconds per read compared to 0.3141 seconds for Python — a 2.26× speedup.
Distribution of Read Times
Retry Attempts Analysis
The DHT11 sensor requires precise timing for communication. When a read fails, the implementations retry with a backoff schedule. Fewer retry attempts indicates more reliable first-attempt reads.
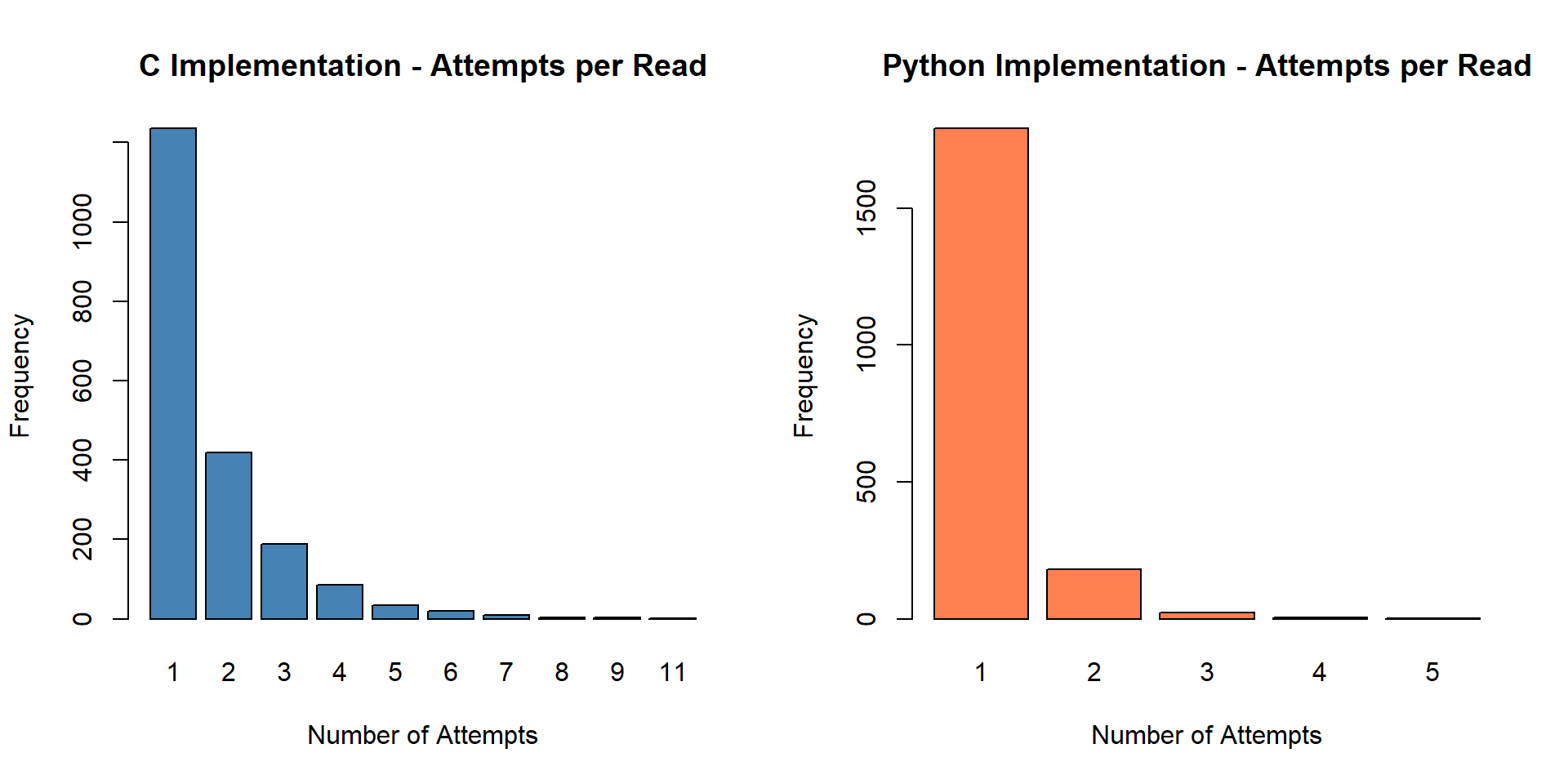
First-attempt success rates: C implementation: 61.8% | Python implementation: 89.6%
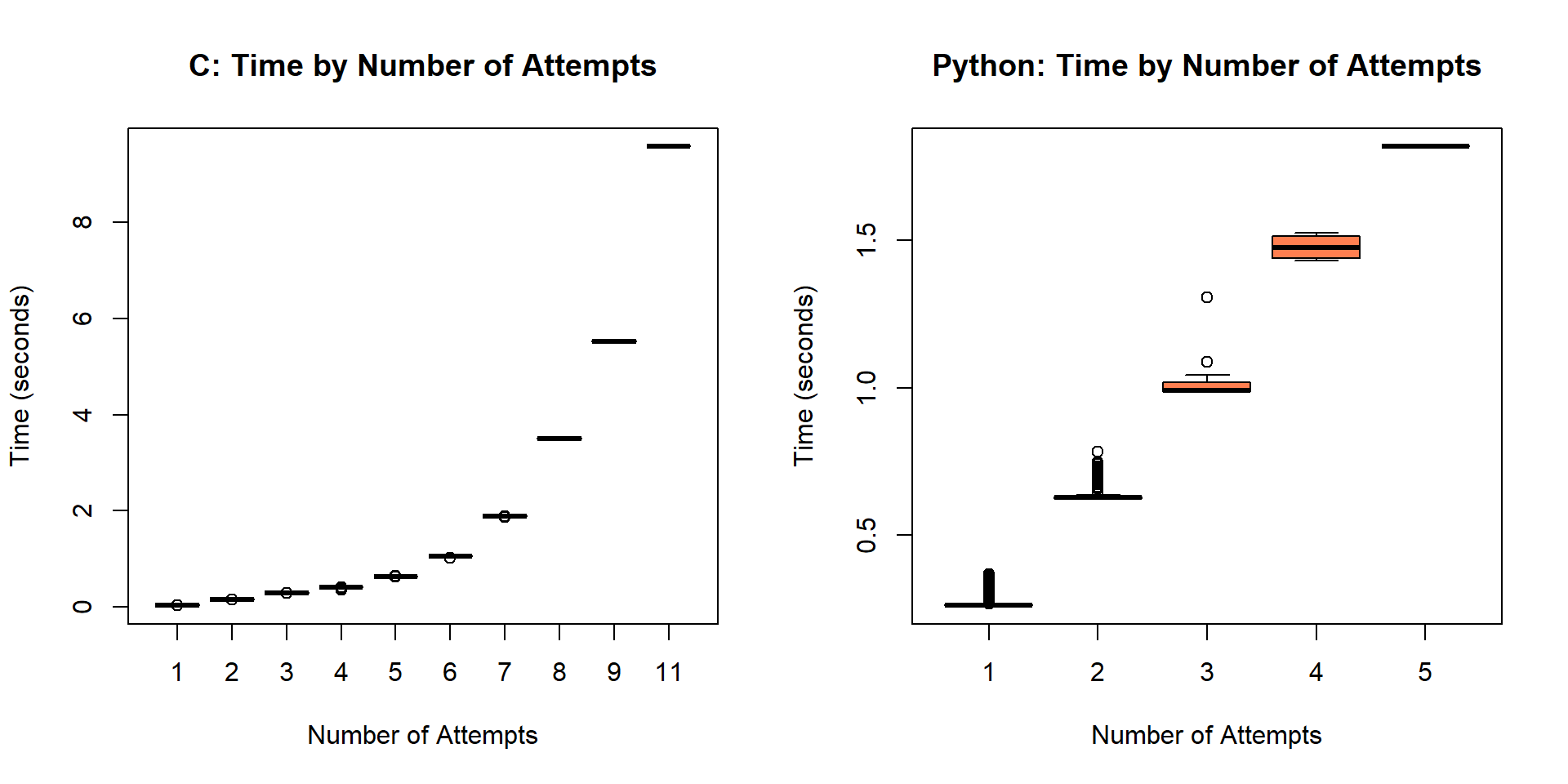
Time vs Attempts Relationship
Cumulative Time Analysis
This shows how the total time accumulates over the benchmark run, demonstrating the overall efficiency difference.
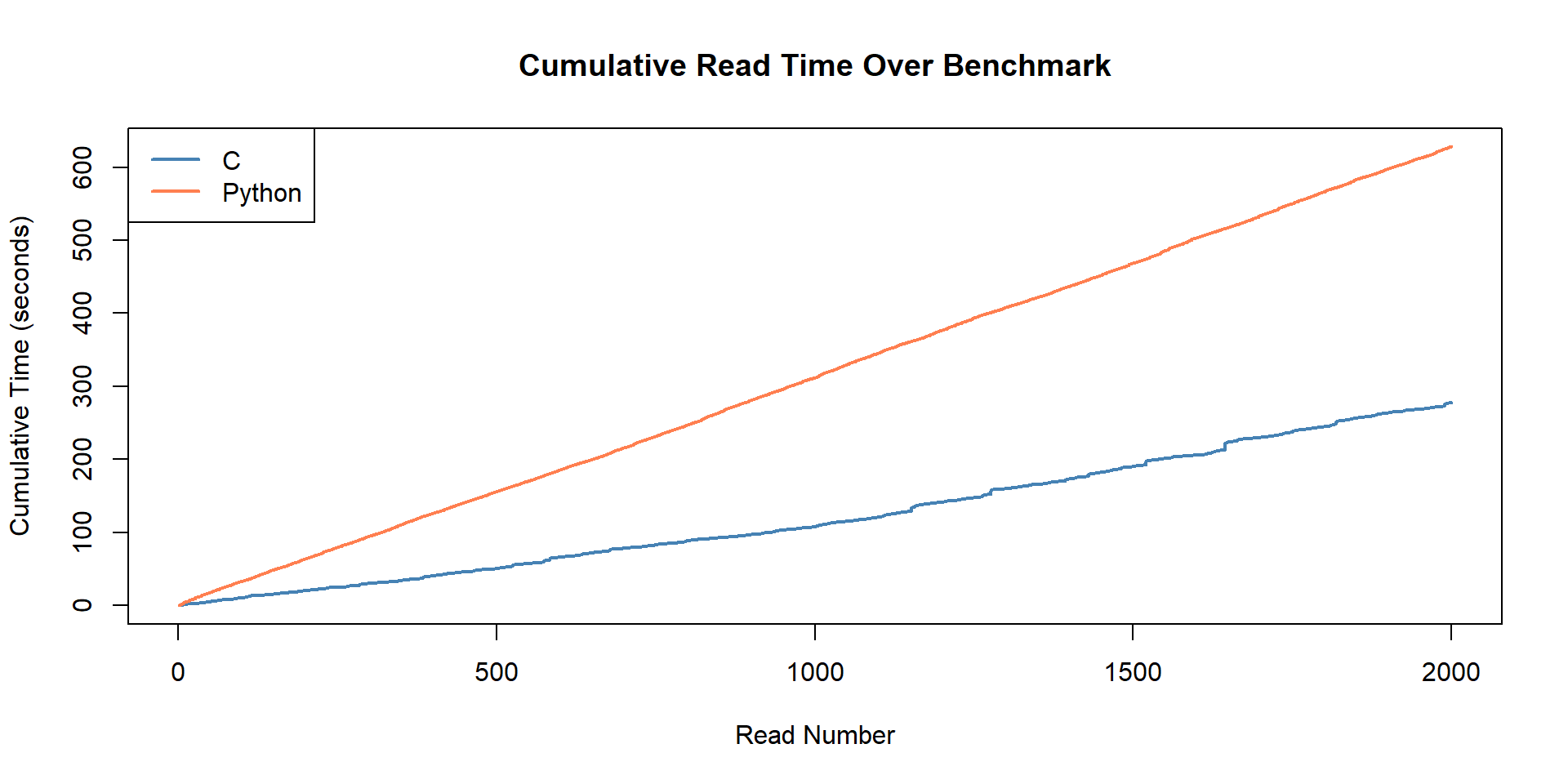
Total benchmark time: C implementation completed in 277.23 seconds vs 628.16 seconds for Python — saving 350.93 seconds (55.9%).
Statistical Comparison
To select an appropriate statistical test, we first assess whether the data are normally distributed using the Shapiro-Wilk test:
- C implementation: W = 0.2501, p = 3.83e-67
- Python implementation: W = 0.4067, p = 9.50e-63
Both distributions depart significantly from normality (p < 0.05), as expected given the right-skewed distribution caused by retry delays. We therefore use the non-parametric Wilcoxon rank-sum test.
- Wilcoxon rank-sum test: W = 594,967.5, p < 0.001
The difference in read times between the C and Python implementations is statistically significant.
Part 2: Full System Benchmarks
This benchmark measures the total end-to-end execution time of running each binary, including process startup, library loading, sensor reading, and JSON output. This reflects real-world usage where the binary is invoked externally (e.g., by a scheduler).
The benchmark script (run_system_benchmarks.sh)
uses /usr/bin/time to measure real, user, and system CPU
time for each invocation.
System Benchmark Summary
| Implementation | Mean Real Time (s) | Median Real Time (s) | SD Real Time (s) | Mean User Time (s) | Mean Sys Time (s) | Success Rate |
|---|---|---|---|---|---|---|
| C (local) | 0.414 | 0.20 | 0.6302 | 0.0018 | 0.0319 | 100% |
| Python (system) | 0.500 | 0.47 | 0.2510 | 0.1462 | 0.0827 | 100% |
Key finding: The C binary averages 0.41 seconds per invocation compared to 0.50 seconds for the Python binary — a 1.21× speedup in total execution time.
Distribution of Execution Times

CPU Time Breakdown
The system benchmark also captures user and system CPU time, showing where time is spent. “I/O Wait” is the difference between real (wall clock) time and CPU time, representing time spent waiting for the sensor to respond.
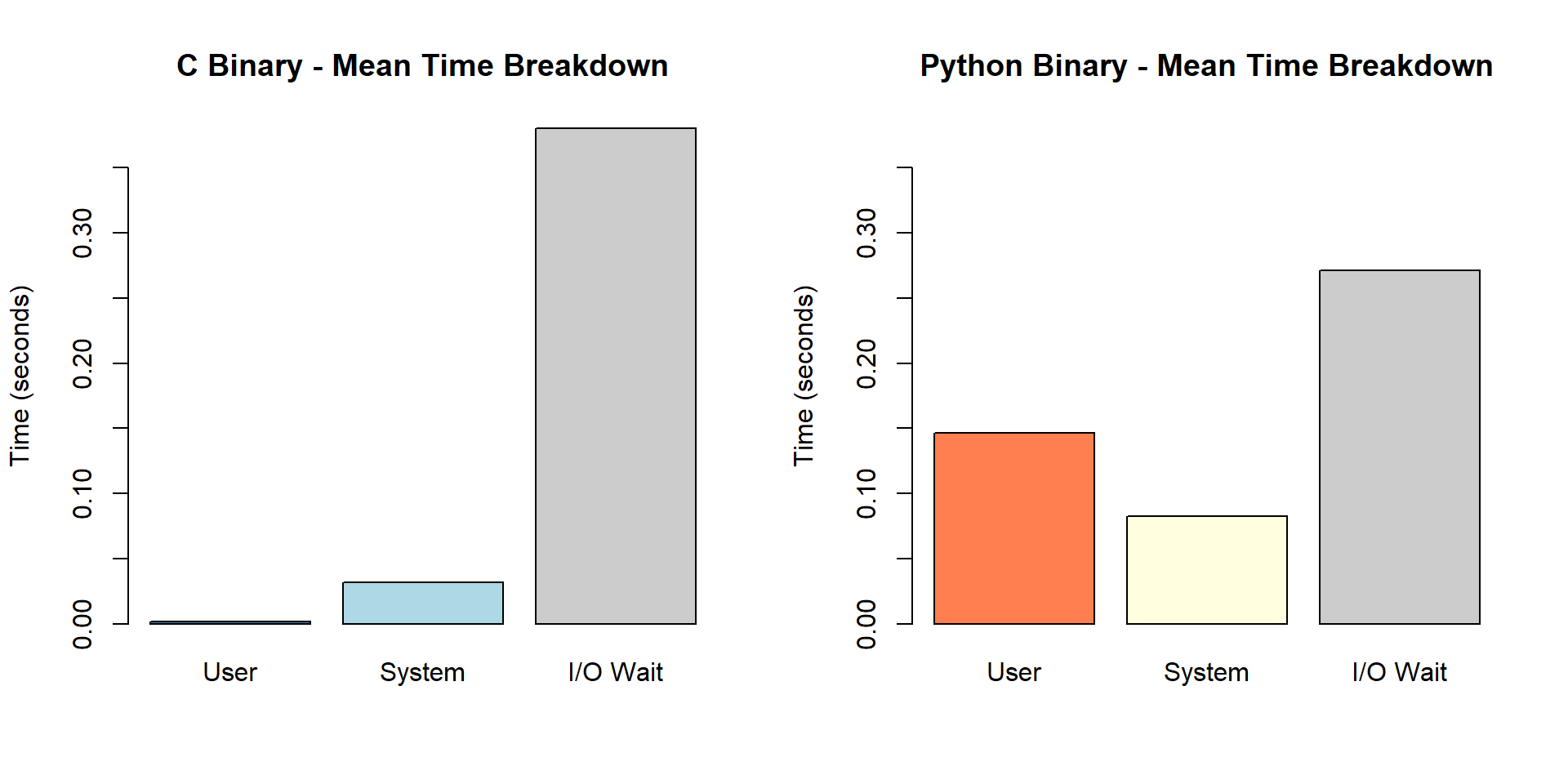
The Python implementation spends significantly more time in user-space CPU (loading interpreter and libraries) compared to the minimal overhead of the C binary.
Conclusions
Two complementary benchmarks demonstrate the performance improvements
from migrating sensor-dht11 from Python to C:
Raw Sensor Reading Performance
Based on 1,999 sensor reads per implementation:
- The C implementation averages 0.139 seconds per read vs 0.314 seconds for Python — a 2.26× speedup.
- The C implementation has a lower first-attempt success rate (61.8% vs 89.6%), but successful first-attempt reads complete in ~0.025s compared to ~0.26s for Python.
- Despite more retries, the C implementation completes the benchmark significantly faster due to lower per-read overhead.
Full System Execution Performance
Based on 100 end-to-end binary invocations:
- The C binary averages 0.41 seconds per invocation vs 0.50 seconds for Python — a 1.21× speedup.
- The Python implementation spends substantially more time in user-space CPU loading the interpreter and libraries.
- The C binary has minimal startup overhead, making it ideal for frequent invocations by external schedulers.
Summary
These results validate the migration from Python to C for the
sensor-dht11 utility, particularly for embedded Raspberry
Pi deployments in the WildlifeSystems project where resource efficiency
is critical.
Annual impact: With 25 sensors reading once per minute, the deployment performs 13,140,000 invocations per year. At a saving of 0.09 seconds per invocation, the C implementation saves approximately 13.1 days of wall-clock time and 29.7 days of CPU time annually across the network.